This page was generated from
docs/Examples/Fitting_Fermi_Diads/Example1c_HORIBA_Calibration/Step1_Fit_Your_Ne_Lines.ipynb.
Interactive online version:
![]() .
.
1. Fitting Ne lines in a loop
This notebook shows how to fit all lines in a folder defined by path
You tweak the fit for a single line, and then use this to fit all lines. You can then refit lines with high residuals/offsets differing from the rest
Downloading locally
You can install DiadFit through PyPI, simply uncomment this line. You only need to run this once per computer (until you want to get an upgraded version)
Uncomment this line if you havent installed DiadFit, or are running a much older version.
[14]:
#!pip install --upgrade DiadFit
Now import the packages you need
When you communicate bugs with Penny, make sure you specify the version here.
[15]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import DiadFit as pf
# This needs to be 0.0.68 or higher!
pf.__version__
[15]:
'0.0.81'
Specifying paths
Put your path here, e.g. where in your computer the spectra and metadata are saved
[16]:
import os
DayFolder=os.getcwd()
# No metadata, just using datestamp
meta_path=DayFolder + '\spectra'
spectra_path=DayFolder + '\spectra'
# Filetype and extension for spectra
spectra_filetype='headless_txt'
spectra_file_ext='.txt'
# file extension for spectra
meta_file_ext='.txt'
# Does your file start with a prefix? E.g 01 Ne_line.txt?
prefix=False
# If so - what is the character separating the prefix from the real name
prefix_str=' '
# Does your instrument have TruPower (WITEC)
TruPower=False
# Save settings to a file to use in all other notebooks
pf.save_settings(meta_path, spectra_path, spectra_filetype, prefix, prefix_str, spectra_file_ext, meta_file_ext, TruPower)
Good job! Filetype headless_txt is valid.
[17]:
# This step gets all your Ne files. Enter ID_str as a string in only your Neon files, exclude strings not in Ne files. So here we take files with 'Ne' in the name and exclude those with 'diad' in the name.
Ne_files=pf.get_files(path=spectra_path,
file_ext=spectra_file_ext, ID_str='Ne',
exclude_str=['diad'], sort=False)
Ne_files
[17]:
['Ne_lines_10_1.txt',
'Ne_lines_10_2.txt',
'Ne_lines_11_1.txt',
'Ne_lines_11_2.txt',
'Ne_lines_12_1.txt',
'Ne_lines_12_2.txt',
'Ne_lines_1_1.txt',
'Ne_lines_1_2.txt',
'Ne_lines_2_1.txt',
'Ne_lines_2_2.txt',
'Ne_lines_3_1.txt',
'Ne_lines_3_2.txt',
'Ne_lines_4_1.txt',
'Ne_lines_4_2.txt',
'Ne_lines_5_1.txt',
'Ne_lines_5_2.txt',
'Ne_lines_6_1.txt',
'Ne_lines_6_2.txt',
'Ne_lines_7_1.txt',
'Ne_lines_7_2.txt',
'Ne_lines_8_1.txt',
'Ne_lines_8_2.txt',
'Ne_lines_9_1.txt',
'Ne_lines_9_2.txt']
Get Ne line positions for your specific laser wavelength
At the moment, this returns any Ne lines with intensity >2000 in the NIST databook, although you can change this!
[18]:
wavelength =532.02 # Specify the specific wavelength of your laser
df_Ne=pf.calculate_Ne_line_positions(wavelength=wavelength,
cut_off_intensity=2000)
df_Ne.head()
[18]:
| Raman_shift (cm-1) | Intensity | Ne emission line in air | |
|---|---|---|---|
| 3 | 392.454898 | 2500.0 | 543.36513 |
| 15 | 819.618059 | 5000.0 | 556.27662 |
| 18 | 819.618059 | 5000.0 | 556.27662 |
| 26 | 1118.005523 | 5000.0 | 565.66588 |
| 33 | 1311.398741 | 5000.0 | 571.92248 |
Calculate the ideal distance between the two lines you are selecting
This finds the closest line in the table above for each selected line
[19]:
line_1=1117
line_2=1447
ideal_split=pf.calculate_Ne_splitting(wavelength=wavelength,
line1_shift=line_1, line2_shift=line_2,
cut_off_intensity=2000)
ideal_split
[19]:
| Ne_Split | Line_1 | Line_2 | Entered Pos Line 1 | Entered Pos Line 2 | |
|---|---|---|---|---|---|
| 0 | 330.477634 | 1118.005523 | 1448.483158 | 1117 | 1447 |
Select one file to tweak the fit for
You can either do this numerically, or by specifiying the filename between ‘’
[20]:
i=0 # Select one file
filename=Ne_files[i]
print(filename)
Ne_lines_10_1.txt
Plot Ne lines to inspect
This function allows you to inspect your spectra, and also uses scipy find peaks to get a first guess of the peak positions, which speeds up the voigt fitting in the later part of the notebook
This also prints the heights of the other peaks so you could choose other Neons if you wanted to
[21]:
exclude_range_1=None
exclude_range_2=None
Neon_id_config=pf.Neon_id_config(height=10, distance=1, prominence=10,
width=1, threshold=0.6,
peak1_cent=line_1, peak2_cent=line_2, n_peaks=6,
exclude_range_1=exclude_range_1,
exclude_range_2=exclude_range_2)
Neon_id_config
Ne, df_fit_params=pf.identify_Ne_lines(path=spectra_path,
filename=filename, filetype=spectra_filetype,
config=Neon_id_config, print_df=False)
df_fit_params
[21]:
| Peak1_cent | Peak1_height | Peak2_cent | Peak2_height | Peak1_prom | Peak2_prom | |
|---|---|---|---|---|---|---|
| 0 | 1117.27 | 11718.0 | 1448.27 | 64525.0 | 11464.0 | 64271.0 |
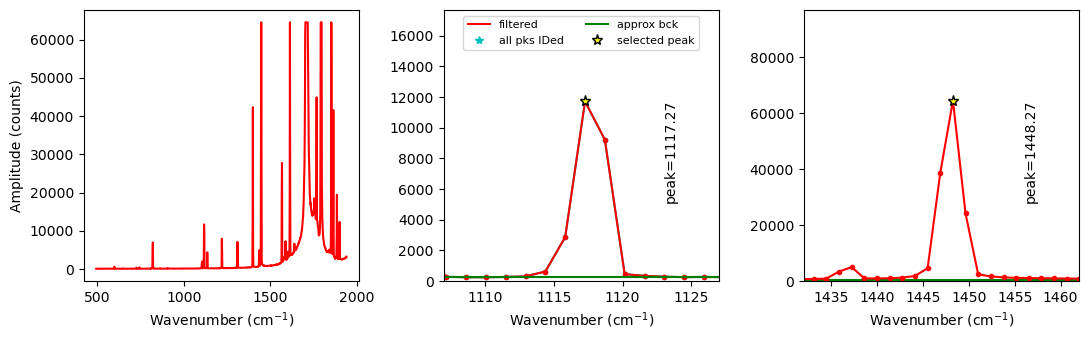
Tweak peak parameters
One important thing is the background positions, these are defined relative to the peak position. Once you tweak them for each instrument, you chould be good to go.
Another thing is how many peaks you want for Peak1, ‘peaks_1’, for the 1117 line, you’ll need 2 if you have the clear secondary peak seen above.
[22]:
pf.Ne_peak_config()
[22]:
Ne_peak_config(model_name='PseudoVoigtModel', N_poly_pk1_baseline=1, N_poly_pk2_baseline=1, lower_bck_pk1=(-50, -25), upper_bck1_pk1=(8, 15), upper_bck2_pk1=(30, 50), lower_bck_pk2=(-44.2, -22), upper_bck1_pk2=(15, 50), upper_bck2_pk2=(50, 51), peaks_1=2, DeltaNe_ideal=330.477634, x_range_baseline_pk1=20, y_range_baseline_pk1=200, x_range_baseline_pk2=20, y_range_baseline_pk2=200, pk1_sigma=0.4, pk2_sigma=0.4, x_range_peak=15, x_range_residual=7, LH_offset_mini=(1.5, 3), x_span_pk1=None, x_span_pk2=None)
[23]:
model_name='PseudoVoigtModel'
Ne_Config_est=pf.Ne_peak_config(model_name=model_name,
DeltaNe_ideal=ideal_split['Ne_Split'], peaks_1=1, LH_offset_mini=[2, 5],
pk1_sigma=1, pk2_sigma=1.5, y_range_baseline_pk1=500, y_range_baseline_pk2=5000,
lower_bck_pk1=(-80, -25), upper_bck1_pk1=[40, 70], upper_bck2_pk1=[40, 70],
lower_bck_pk2=[-40, -20], upper_bck1_pk2=[10, 15], upper_bck2_pk2=[25, 40],
x_range_peak=15, x_span_pk1=[-5, 5], x_span_pk2=[-5, 5],
N_poly_pk2_baseline=2)
[24]:
df_test_params=pf.fit_Ne_lines(Ne=Ne, filename=filename,
path=spectra_path, prefix=prefix,
config=Ne_Config_est,
Ne_center_1=df_fit_params['Peak1_cent'].iloc[0],
Ne_center_2=df_fit_params['Peak2_cent'].iloc[0],
Ne_prom_1=df_fit_params['Peak1_prom'].iloc[0],
Ne_prom_2=df_fit_params['Peak2_prom'].iloc[0],
const_params=False)
display(df_test_params)
| filename | 1σ_Ne_Corr_test | 1σ_Ne_Corr | pk2_peak_cent | pk2_amplitude | pk2_sigma | pk2_gamma | error_pk2 | Peak2_Prop_Lor | pk1_peak_cent | ... | pk1_gamma | error_pk1 | Peak1_Prop_Lor | deltaNe | Ne_Corr | Ne_Corr_min | Ne_Corr_max | residual_pk2 | residual_pk1 | residual_pk1+pk2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Ne_lines_10_1.txt | 0.000166 | 0.000166 | 1448.04996 | 181451.221685 | 1.300963 | None | 0.0189 | 0.014034 | 1117.778337 | ... | None | 0.051605 | 0.127653 | 330.271623 | 1.000624 | 1.00041 | 1.000837 | 511.827769 | 267.574636 | 779.402405 |
1 rows × 22 columns
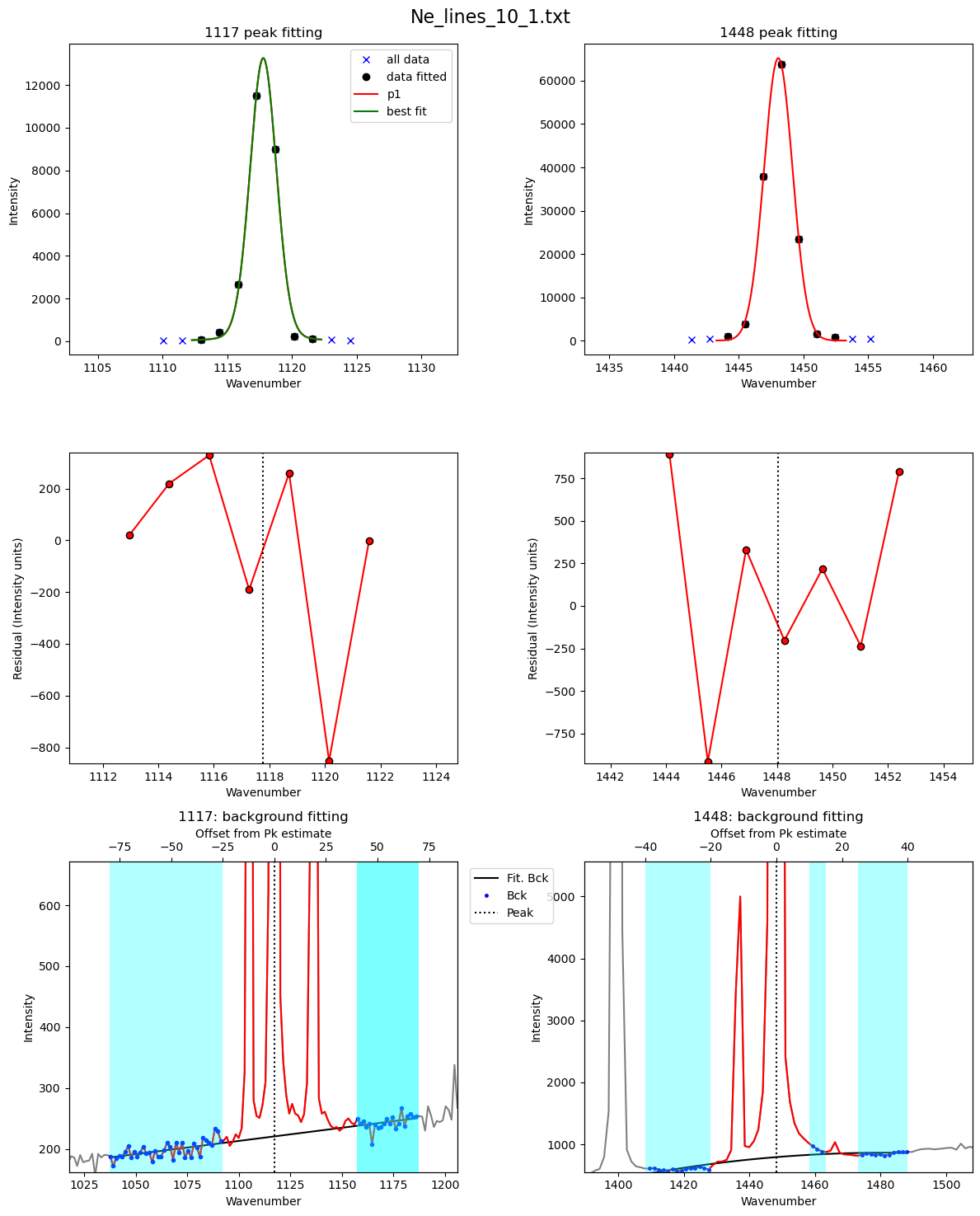
[25]:
## Now tweak the values of the sigma to help with the looping - then for looping we let these parameters only vary +-20% between spectra
Ne_Config_est.pk1_sigma=df_test_params['pk1_sigma'][0]
Ne_Config_est.pk2_sigma=df_test_params['pk2_sigma'][0]
Now fit all Ne files here using these parameters.
If you select plot_figure=False, the loop will be quick.
But if its True, you can to inspect the figures.
[26]:
df2=pf.loop_Ne_lines(files=Ne_files, spectra_path=spectra_path,
filetype=spectra_filetype, config_ID_peaks=Neon_id_config, config=Ne_Config_est,
df_fit_params=df_fit_params, prefix=prefix,
plot_figure=True, const_params=True)
c:\users\penny\box\berkeley_new\diadfit_outer\src\DiadFit\ne_lines.py:1285: RuntimeWarning: More than 20 figures have been opened. Figures created through the pyplot interface (`matplotlib.pyplot.figure`) are retained until explicitly closed and may consume too much memory. (To control this warning, see the rcParam `figure.max_open_warning`). Consider using `matplotlib.pyplot.close()`.
fig, ((ax3, ax2), (ax5, ax4), (ax1, ax0)) = plt.subplots(3,2, figsize = (12,15)) # adjust dimensions of figure here
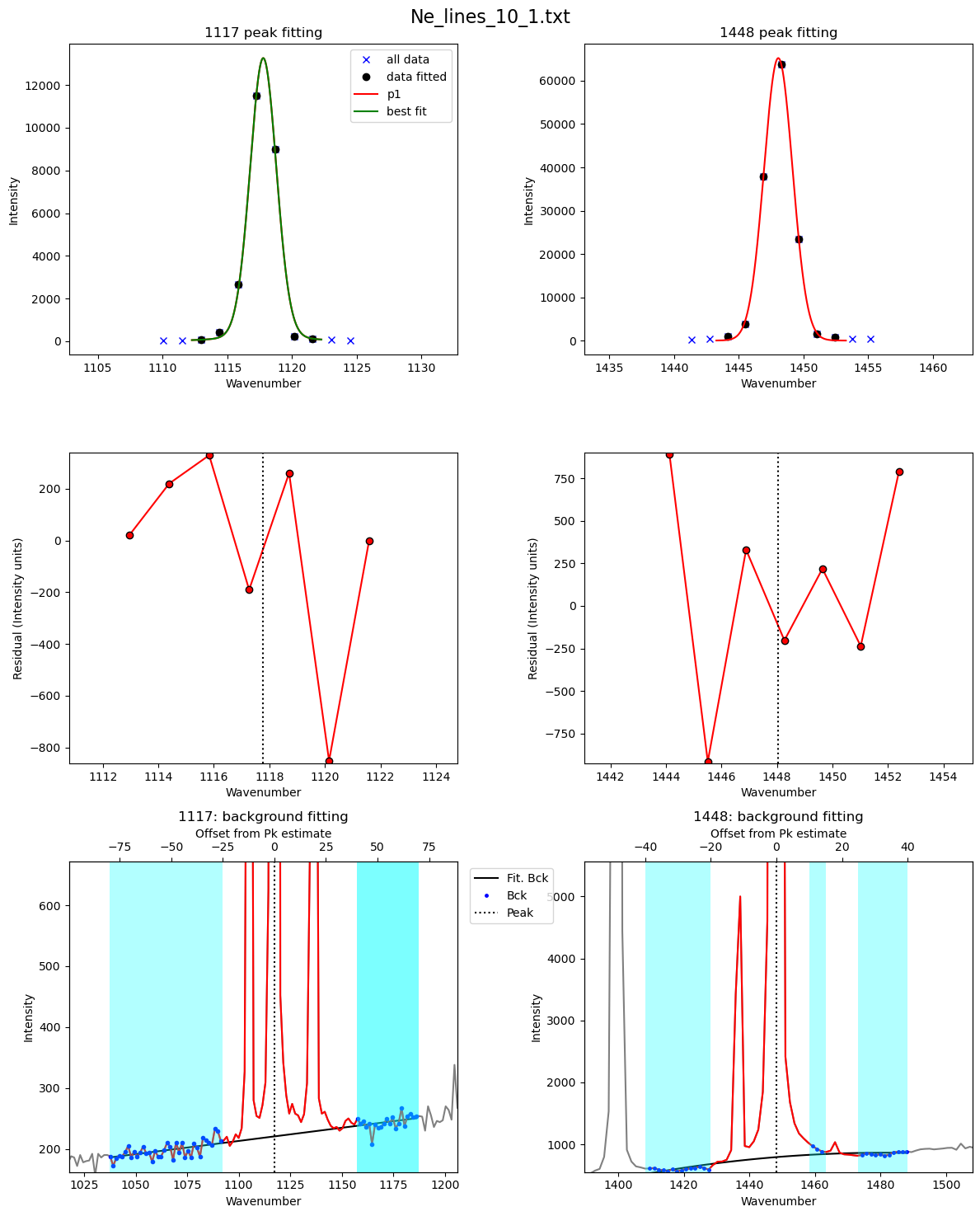
Now extract metadata to get a timestamp for each file
[27]:
## Get meta files
Ne_files_meta=pf.get_files(path=meta_path,
file_ext=meta_file_ext, ID_str='Ne',
exclude_str=['diad'], sort=False)
Ne_files_meta[0:5]
[27]:
['Ne_lines_10_1.txt',
'Ne_lines_10_2.txt',
'Ne_lines_11_1.txt',
'Ne_lines_11_2.txt',
'Ne_lines_12_1.txt']
[28]:
meta=pf.loop_convert_datastamp_to_metadata(path=spectra_path,
files=Ne_files, creation=False,
modification=True)
meta
[28]:
| filename | date | Month | Day | power (mW) | Int_time (s) | accumulations | Mag (X) | duration | 24hr_time | sec since midnight | Spectral Center | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Ne_lines_1_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 1:58:25 | 7105 | NaN |
| 0 | Ne_lines_1_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 2:0:27 | 7227 | NaN |
| 0 | Ne_lines_2_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 2:15:55 | 8155 | NaN |
| 0 | Ne_lines_2_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 2:20:34 | 8434 | NaN |
| 0 | Ne_lines_3_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 2:56:49 | 10609 | NaN |
| 0 | Ne_lines_3_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 3:0:8 | 10808 | NaN |
| 0 | Ne_lines_4_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 3:32:38 | 12758 | NaN |
| 0 | Ne_lines_4_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 3:39:53 | 13193 | NaN |
| 0 | Ne_lines_6_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 4:31:37 | 16297 | NaN |
| 0 | Ne_lines_6_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 4:33:10 | 16390 | NaN |
| 0 | Ne_lines_5_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 4:8:8 | 14888 | NaN |
| 0 | Ne_lines_5_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 4:9:24 | 14964 | NaN |
| 0 | Ne_lines_7_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 5:10:8 | 18608 | NaN |
| 0 | Ne_lines_7_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 5:12:22 | 18742 | NaN |
| 0 | Ne_lines_8_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 5:54:23 | 21263 | NaN |
| 0 | Ne_lines_8_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 5:57:28 | 21448 | NaN |
| 0 | Ne_lines_9_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 6:53:17 | 24797 | NaN |
| 0 | Ne_lines_9_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 6:55:17 | 24917 | NaN |
| 0 | Ne_lines_10_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 7:23:4 | 26584 | NaN |
| 0 | Ne_lines_10_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 7:25:23 | 26723 | NaN |
| 0 | Ne_lines_11_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 8:13:31 | 29611 | NaN |
| 0 | Ne_lines_11_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 8:15:45 | 29745 | NaN |
| 0 | Ne_lines_12_1.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 9:4:28 | 32668 | NaN |
| 0 | Ne_lines_12_2.txt | January 1, 2020 | January | 1 | NaN | NaN | NaN | NaN | NaN | 9:6:35 | 32795 | NaN |
[29]:
# This is getting the metadata file names. Check here the prefix has been removed.
file_m=pf.extracting_filenames_generic(names=meta['filename'],
file_ext='.txt')
file_m
good job, no duplicate file names
[29]:
array(['Ne_lines_1_1', 'Ne_lines_1_2', 'Ne_lines_2_1', 'Ne_lines_2_2',
'Ne_lines_3_1', 'Ne_lines_3_2', 'Ne_lines_4_1', 'Ne_lines_4_2',
'Ne_lines_6_1', 'Ne_lines_6_2', 'Ne_lines_5_1', 'Ne_lines_5_2',
'Ne_lines_7_1', 'Ne_lines_7_2', 'Ne_lines_8_1', 'Ne_lines_8_2',
'Ne_lines_9_1', 'Ne_lines_9_2', 'Ne_lines_10_1', 'Ne_lines_10_2',
'Ne_lines_11_1', 'Ne_lines_11_2', 'Ne_lines_12_1', 'Ne_lines_12_2'],
dtype=object)
[30]:
# This is getting the spectra file names. Check that they are in the same format as the metadataones above, this is what you need to successfully stitch together.
file_s=pf.extracting_filenames_generic(names=df2['filename'],
file_ext='.txt')
file_s
good job, no duplicate file names
[30]:
array(['Ne_lines_10_1', 'Ne_lines_10_2', 'Ne_lines_11_1', 'Ne_lines_11_2',
'Ne_lines_12_1', 'Ne_lines_12_2', 'Ne_lines_1_1', 'Ne_lines_1_2',
'Ne_lines_2_1', 'Ne_lines_2_2', 'Ne_lines_3_1', 'Ne_lines_3_2',
'Ne_lines_4_1', 'Ne_lines_4_2', 'Ne_lines_5_1', 'Ne_lines_5_2',
'Ne_lines_6_1', 'Ne_lines_6_2', 'Ne_lines_7_1', 'Ne_lines_7_2',
'Ne_lines_8_1', 'Ne_lines_8_2', 'Ne_lines_9_1', 'Ne_lines_9_2'],
dtype=object)
Combine 2 dataframes
Here we add a new column to each dataframe with these stripped back names, and then merge the 2 dataframes
[31]:
meta['name_for_matching']=file_m
df2['name_for_matching']=file_s
df_combo=df2.merge(meta, on='name_for_matching')
Now lets inspect changes in Ne correction factor with time
Normally, you can spot outliers this way
[32]:
df_combo_sort=df_combo.sort_values(by='sec since midnight')
df_combo_sort.to_excel('PseudoVoigt.xlsx')
[33]:
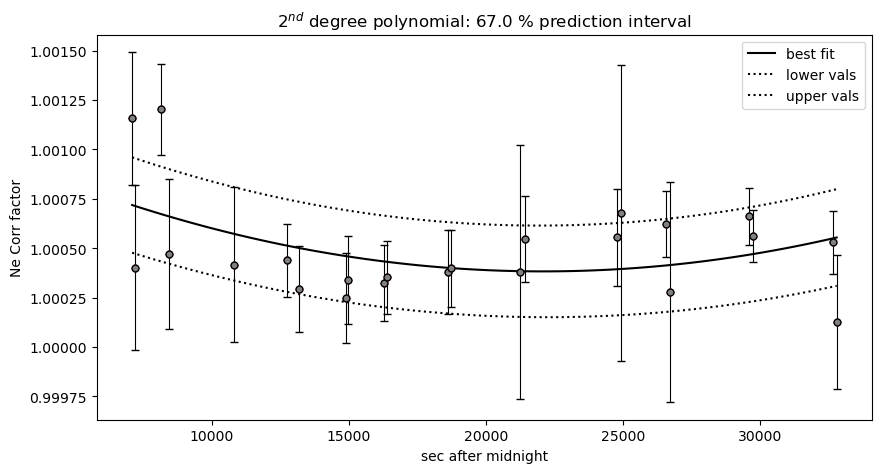
fig=pf.plot_Ne_corrections(df=df_combo, x_axis=df_combo['sec since midnight'],
x_label='secs since midnight')
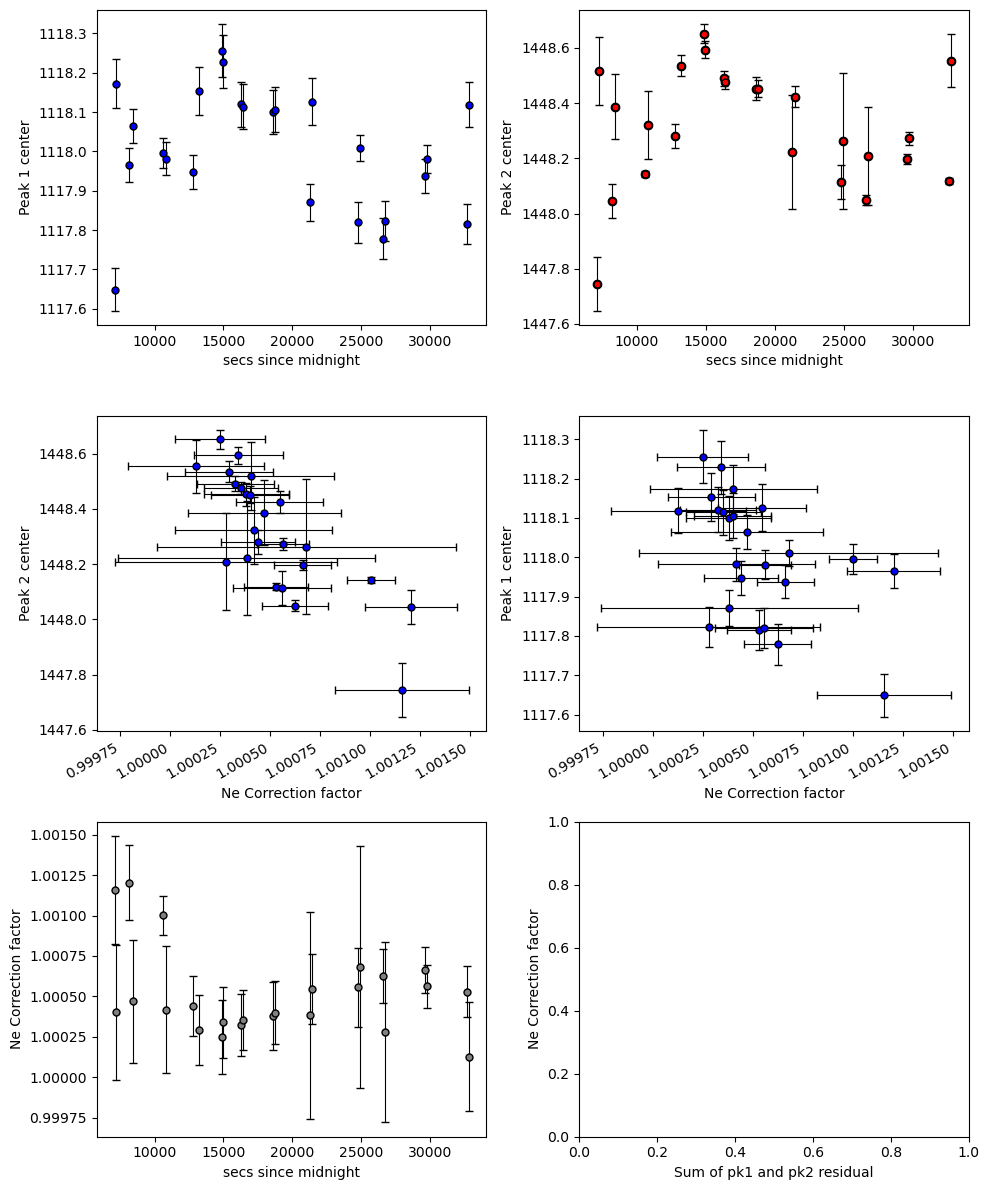
Exclude ones that don’t look right…
The filter_Ne_Line_neighbours excludes Ne lines that have a correction factor more than “offset” from their N neighbours (defined by “number_av”)
Tweak offset and number_av until you exclude the ones that dont look right
Smaller number of offset - more discarded
If you notice really bad fits, you can also exclude certain files like file_name_filt=[‘Ne_line_1.txt’], or file_name_filt=[‘Ne_line_2.txt’, ‘Ne_line_5.txt’]
[34]:
# You can see there is no coherent trends, whcih is why we decided not to use Ne lines for the Cambridge raman
# The peak fits are too noisy.
filt=pf.filter_Ne_Line_neighbours(df_combo=df_combo,
number_av=3, offset=0.0005, file_name_filt=None)
# Now lets plot this to see
fig, (ax1) = plt.subplots(1, 1, figsize=(8,4))
ax1.errorbar(df_combo['sec since midnight'], df_combo['Ne_Corr'], xerr=0,
yerr=df_combo['1σ_Ne_Corr'], fmt='d', ecolor='k', elinewidth=0.8, mfc='cyan', ms=1, mec='k', capsize=3)
ax1.plot(df_combo['sec since midnight'], df_combo['Ne_Corr'], 'ok', label='Removed')
ax1.plot(df_combo['sec since midnight'], filt, 'or', label='Keep')
ax1.legend()
ax1.set_xlabel('Sec since midnight (s)')
ax1.set_ylabel('Ne Correction factor')
ax1.set_title('All measurements')
fig.tight_layout()
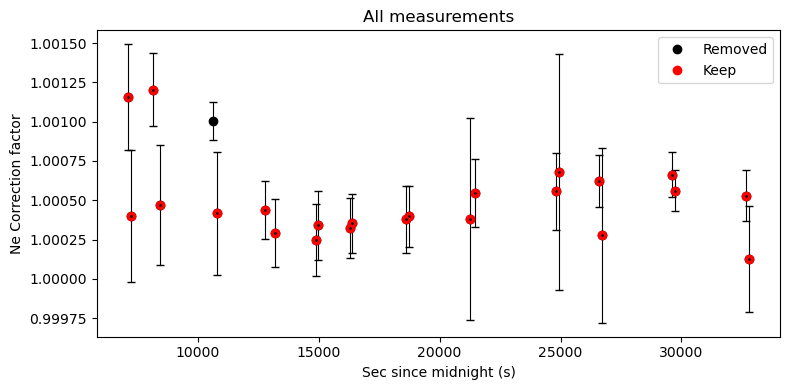
Now lets make a regression against time
We take this time regression and then apply to our diad fits
We can see that at the resolution of this instrment, the Ne line correction model is basically useless. The fit errors are simply too large
[35]:
big_err=df_combo['1σ_Ne_Corr']>0.001
## Lets get filtered ones
keep=(filt>0)&(~big_err)
pf.generate_Ne_corr_model(time=df_combo['sec since midnight'].loc[keep], Ne_corr=df_combo.loc[keep],
N_poly=2, CI=0.67, pkl_name='Neon_corr_model.pkl')